삽 대신 굴삭기 — Netflix가 400개 PostgreSQL 클러스터를 자동으로 옮긴 방법
Netflix Online Data Stores 팀이 400개에 가까운 RDS Postgres 클러스터를 Aurora Postgres로 자동 마이그레이션한 셀프서비스 워크플로우 설계 과정.
운하를 판다고 상상해보자. 삽으로 팔 수도 있고, 굴삭기를 쓸 수도 있다. 삽으로 한두 미터는 가능하지만, 400킬로미터를 삽으로 파는 건 광기에 가깝다. Netflix는 약 400개의 PostgreSQL 클러스터를 RDS에서 Aurora로 마이그레이션해야 했다. 수동으로 하나씩? 말도 안 된다. 그래서 굴삭기를 만들었다 — 셀프서비스 자동화 파이프라인이라는 이름의.
왜 Aurora인가
2024년, Netflix의 Online Data Stores 팀은 사내 관계형 데이터베이스 기술을 전면 재평가했다. 기능, 성능, 총 소유 비용(TCO)을 모두 따져본 결론은 명확했다. Amazon Aurora PostgreSQL을 표준 관계형 데이터베이스로 채택하기로 한 것이다.
근거는 세 가지였다.
- PostgreSQL이 이미 Netflix 관계형 워크로드의 대다수를 처리하고 있었다.
- 내부 평가에서 Aurora PostgreSQL이 기존 관계형 DB 워크로드의 95% 이상을 지원할 수 있었다.
- Aurora의 분산 스토리지 아키텍처가 확장성, 고가용성, 탄력성에서 뚜렷한 이점을 제공했다.
[💡 잠깐! 이 용어는?] Aurora PostgreSQL: AWS의 클라우드 네이티브 관계형 데이터베이스다. PostgreSQL 호환이면서 스토리지가 자동 확장되고, 최대 15개의 읽기 전용 복제본을 지원하는 분산 아키텍처를 갖추고 있다.
기술적 난관 — 왜 자동화가 필수였나
단순히 데이터를 복사하면 될 것 같지만, 현실은 훨씬 복잡하다. 이사할 때 짐만 옮기는 게 아니라 전기, 수도, 인터넷, 주소 변경까지 전부 처리해야 하는 것과 똑같다.
- 제로 데이터 손실: 매우 짧은 시간 내에 모든 데이터가 빠짐없이 이전되어야 한다.
- 최소 다운타임: 핵심 서비스는 쓰기 중단 시간을 극도로 짧게 유지해야 한다.
- 클라이언트 앱 제어 불가: 플랫폼 팀이 DB를 관리하지만, 읽기/쓰기는 애플리케이션 팀 소관이다. 임의로 멈출 수 없다.
- RDS 자격 증명 직접 접근 불가: 복제, 정지, 검증을 DB 자격 증명 없이 수행해야 한다.
- 성능 저하 없음: Aurora에서 기존과 동일하거나 더 나은 성능을 보장해야 한다.
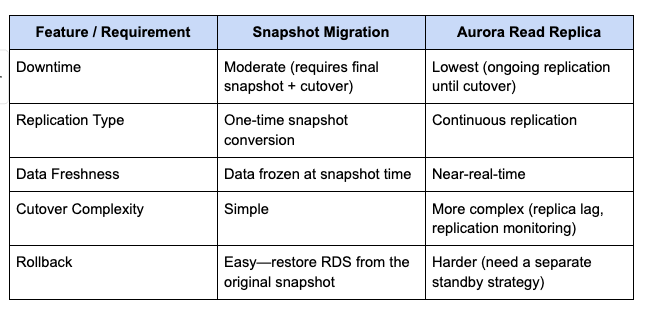
마이그레이션 기법 비교
| 기준 | 스냅샷 방식 | Aurora Read Replica 방식 |
|---|---|---|
| 다운타임 | 길다 (스냅샷 생성 + 변환 + 복원) | 짧다 (연속 복제 후 프로모션) |
| 구현 복잡도 | 낮음 | 높음 |
| 실시간 동기화 | 없음 (시점 고정) | 있음 (WAL 스트리밍) |
| 프로덕션 적합성 | 낮음 | 높음 |
| 사전 검증 가능 | 제한적 | 가능 (복제본에서 테스트) |
Netflix는 구현이 어렵더라도 다운타임을 최소화할 수 있는 Aurora Read Replica 방식을 택했다.
4단계 자동화 파이프라인
1단계: 데이터 복제 (Replication)
원본 RDS에서 자동 백업을 활성화한 뒤, Aurora Read Replica를 일관된 스냅샷으로 초기화한다. 이후 WAL(Write-Ahead Log) 레코드의 연속 스트리밍으로 동기 상태를 유지한다.
# RDS 호환 파라미터를 Aurora 파라미터 그룹으로 이전
# 지원되지 않거나 동작이 다른 파라미터는 Aurora 모범 사례에 따라 조정
memory_configuration: "migrate"
connection_limits: "migrate"
query_planner_behavior: "migrate"
aurora_incompatible_params: "omit_or_adjust"[💡 잠깐! 이 용어는?] WAL(Write-Ahead Log): PostgreSQL이 데이터 변경 사항을 디스크에 기록하기 전에 먼저 로그에 기록하는 메커니즘이다. 장애 복구와 복제의 핵심 기반이며, Aurora Read Replica도 이 WAL 스트리밍으로 원본과 동기화를 유지한다.
2단계: 정지 (Quiescence)
쓰기 트래픽을 완전히 멈추는 단계다. 수술 전에 환자를 마취하는 것과 같다.
먼저 사용자에게 애플리케이션 레벨의 트래픽 중단을 요청한다. 하지만 사람의 요청만으로는 충분하지 않다. Netflix는 인프라 레이어에서도 이중으로 차단한다. RDS 인스턴스의 보안 그룹을 분리해 새 인바운드 연결을 막고, 인스턴스를 리부트해 기존 연결을 강제 종료한다. DB 자격 증명에 접근하지 않으면서도 완전한 정지를 보장하는 메커니즘이다.
3단계: 검증 (Validation)
Aurora Read Replica가 원본을 완전히 따라잡았는지 OldestReplicationSlotLag 메트릭으로 확인한다.
SELECT slot_name,
pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn) AS slot_lag_bytes
FROM pg_replication_slots;흥미로운 함정이 있다. 이 메트릭은 0과 64MB 사이를 오간다. 유휴 상태의 PostgreSQL은 약 5분마다 빈 WAL 세그먼트 로테이션을 수행하는데(archive_timeout = 300s), 새 세그먼트 시작 직후 Aurora가 아직 이를 소비하지 못해 지연이 64MB(WAL 세그먼트 크기)로 뜬다. 지연이 0으로 떨어지는 순간이 모든 의미 있는 WAL 레코드가 완전히 복제되었음을 의미한다.
4단계: 컷오버 (Cutover)
Aurora Read Replica를 독립적인 쓰기 가능 Aurora PostgreSQL 클러스터로 프로모션한다.
# Netflix DAL 아키텍처
# 앱 → Forward Proxy(mTLS) → Data Gateway(Envoy) → DB
#
# 컷오버: Data Gateway의 런타임 설정만 변경
envoy_route_config:
destination: "aurora-writer-endpoint" # RDS → Aurora로 변경
# 앱 코드 변경 없음, DB 자격 증명 접근 없음Netflix의 Data Access Layer(DAL) 아키텍처가 빛을 발하는 순간이다. 애플리케이션 코드 한 줄 건드리지 않고, Envoy 기반 Data Gateway의 설정만 업데이트하면 모든 클라이언트 연결이 투명하게 Aurora로 향한다.
실전 사례 — 파트너 플랫폼 마이그레이션
Netflix의 Enablement Applications 팀이 첫 번째 실제 마이그레이션을 수행했다. 이 팀은 디바이스 제조사, 유통 파트너 등 Netflix 전체 파트너 통합 생태계를 모델링하는 DB를 관리한다.
[💡 잠깐! 이 용어는?] flowlogs: Netflix 내부의 eBPF 기반 네트워크 귀속 도구다. TCP 플로우 데이터를 캡처해 DB에 연결하는 모든 서비스와 애플리케이션을 식별한다. 문서화되지 않은 숨은 클라이언트까지 마이그레이션 계획에 포함시킬 수 있다.
준비 과정의 핵심은 세 가지였다.
- 트래픽 패턴 파악: CloudWatch 메트릭으로 PostgreSQL 연결 수, 읽기/쓰기 패턴, 전체 부하를 분석해 기준선을 수립했다.
- 모든 DB 소비자 식별:
flowlogs로 문서에 없는 숨은 소비자까지 빠짐없이 열거했다. - 이해관계자 소통 채널 구축: 타임라인, 준비 상태 체크, 컷오버 알림을 공유하는 전용 채널을 만들었다.
마무리
400개 클러스터를 하나씩 수동으로 옮기겠다는 건 삽으로 운하를 파겠다는 것과 같다. Netflix의 사례에서 핵심은 셀프서비스 자동화가 대규모 마이그레이션의 유일한 해법이라는 것이다. DAL 같은 추상화 레이어가 갖춰져 있다면, 마이그레이션 컷오버가 설정 한 줄 변경으로 줄어든다. 인프라 추상화에 대한 선행 투자가 이런 순간에 엄청난 레버리지를 제공한다.
같은 카테고리 · Backend
비슷한 주제의 최신 글



태그가 겹치는 글
공통 태그가 많을수록 위에 보인다