신입사원을 에이스로 — Netflix가 LLM Post-Training을 대규모 엔지니어링으로 만든 과정
Pre-training이 LLM에 넓은 언어 능력을 주지만, post-training이 실제 의도와 도메인 제약에 맞추는 단계. Netflix의 스케일링 접근법.
신입사원을 떠올려보자. 명문대를 졸업하고 기본기는 탄탄하지만, 회사의 카탈로그 구조, 사용자 행동 패턴, 내부 용어를 모른다. 이 신입에게 "Netflix 추천 시스템을 맡겨"라고 하면? 당연히 온보딩이 필요하다. LLM도 마찬가지다. Pre-training은 대학 교육이고, Post-training은 회사 온보딩이다. Netflix AI Platform 팀은 이 온보딩 과정을 단순한 스크립트 모음이 아니라 프레임워크 수준의 시스템으로 만들었다.
Post-Training — 범용에서 전문으로
Pre-training을 마친 LLM은 넓은 언어 능력과 세계 지식을 갖고 있다. 하지만 특정 도메인의 의도(intent), 제약(constraint), 프로덕션 안정성 요구사항에는 맞춰져 있지 않다. Post-training이 이 간극을 메운다.
Netflix는 추천, 개인화, 검색 영역에서 LLM을 활용하고 있다. 범용 파운데이션 모델을 Netflix 카탈로그와 사용자 상호작용 이력의 미묘한 결을 반영하도록 적응시키는 작업이 핵심이다.
[💡 잠깐! 이 용어는?] Post-Training: Pre-training 이후에 수행되는 모든 학습 과정의 총칭이다. SFT(지도 미세조정), DPO(직접 선호 최적화), RLHF(인간 피드백 기반 강화학습) 등이 포함된다.
스크립트와 프로덕션 시스템 사이의 심연
실험 수준에서 post-training은 간단하다. 데이터 준비하고, Hugging Face에서 모델 로드하고, 배치 돌리면 끝이다. 몇 줄의 코드면 충분하다.
그런데 Netflix 규모로 올라가면 완전히 다른 게임이 된다. 요리 비유가 딱 맞다. 집에서 파스타 한 그릇 만드는 건 쉽다. 하지만 매일 수만 명에게 일정한 품질의 파스타를 제공하려면? 식재료 공급망, 주방 설비, 품질 관리 시스템, 인력 배치까지 전부 엔지니어링이 된다.
데이터 — 어떤 토큰에서 배울 것인가
고품질 post-training에서는 손실을 계산할 토큰을 정밀하게 제어해야 한다. 프롬프트나 시스템 메시지에서는 학습하지 않고, 어시스턴트 응답 토큰만 최적화하도록 명시적 손실 마스킹이 필요하다.
def apply_loss_mask(tokens, roles):
mask = [1 if role == "assistant" else 0 for role, token in zip(roles, tokens)]
return mask가변 길이 시퀀스도 골칫거리다. 배치 내 패딩은 연산 낭비이고, FSDP 워커 간 불균일한 shape은 GPU 동기화 오버헤드를 유발한다. Netflix는 비동기 온더플라이 시퀀스 패킹으로 해결했다. CPU에서 패킹 작업을 수행하는 동안 GPU는 학습을 계속하는 구조다. 가장 편차가 큰 데이터셋에서 유효 토큰 처리량이 최대 4.7배 향상되었다.
[💡 잠깐! 이 용어는?] FSDP(Fully Sharded Data Parallelism): 모델의 파라미터, 그래디언트, 옵티마이저 상태를 여러 GPU에 분산(샤딩)시켜 메모리 사용량을 줄이는 분산 학습 기법이다. 단일 GPU에 안 들어가는 대형 모델을 학습할 때 필수다.
모델 — 단일 GPU의 벽을 넘어
모델이 단일 GPU에 들어가지 않으면 FSDP나 Tensor Parallelism 같은 샤딩 전략이 필요하다. 풀 파인튜닝 vs LoRA, 활성화 체크포인팅, 정밀도 설정(특히 RL에서 rollout과 policy의 정밀도를 맞추는 것) 등 고려 사항이 산더미다.
12만 8천 이상의 대형 어휘(vocabulary)는 또 다른 함정이다. 로짓 텐서가 [batch, seq_len, vocab] 크기로 메모리를 폭발시킬 수 있다. 12만 8천 명의 지원자 전원에게 매번 점수를 매기는 면접관을 떠올리면 된다. 어휘가 커질수록 연산과 메모리 부담이 선형적으로 증가한다.
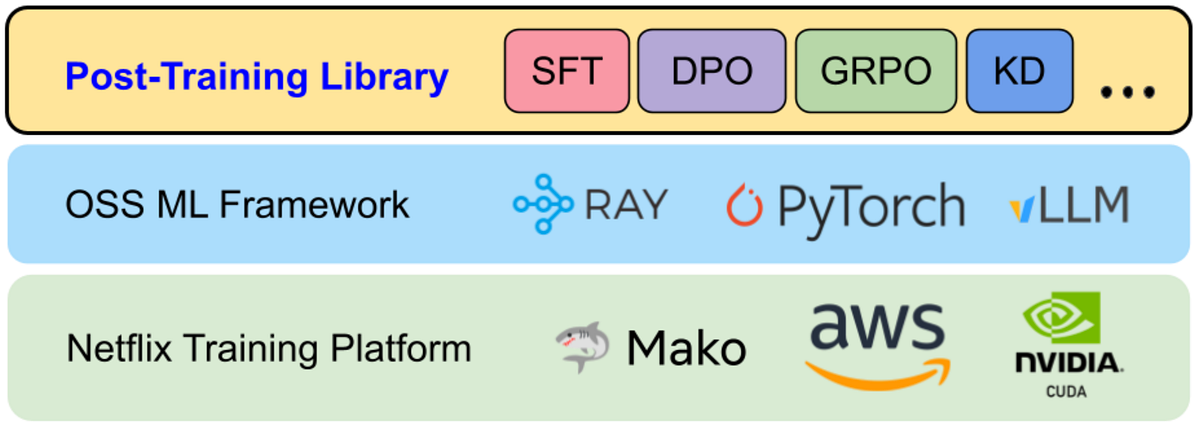
프레임워크 아키텍처 — 네 개의 기둥
Netflix의 프레임워크는 네 가지 기둥 위에 세워졌다.
| 기둥 | 역할 | 핵심 기능 |
|---|---|---|
| Data | 데이터 관리 | SFT/보상 모델링/RL용 데이터셋 추상화, 클라우드 스트리밍, 비동기 시퀀스 패킹 |
| Model | 모델 정의 | Qwen3/Gemma3/MoE 지원, LoRA 통합, 고수준 샤딩 API |
| Compute | 연산 관리 | 단일 노드~수백 GPU 통합 인터페이스, MFU 모니터링, 체크포인팅 |
| Workflow | 워크플로우 오케스트레이션 | SFT부터 온라인 RL까지, 하이브리드 단일 컨트롤러 + SPMD 실행 모델 |
인프라 스택은 아래에서 위로 이렇게 쌓인다. Mako(Netflix 내부 ML 컴퓨트 플랫폼, AWS GPU 프로비저닝) → PyTorch + Ray + vLLM → Post-Training 프레임워크(라이브러리). 사용자는 설정 파일로 레시피를 선택하고, 태스크별 컴포넌트를 꽂는 형태로 학습 잡을 정의한다.
[💡 잠깐! 이 용어는?] MFU(Model FLOPS Utilization): GPU의 이론적 최대 연산 성능 대비 실제로 모델 학습에 사용되는 연산 비율이다. MFU가 높을수록 GPU를 효율적으로 쓰고 있다는 뜻이다.
SFT에서 RL로 — 실행 모델의 진화
처음 설계할 때는 SFT가 중심이었다. 비교적 정적인 데이터 흐름, 단일 학습 루프, SPMD 실행 모델로 충분했다. 그런데 2025년, DeepSeek-R1과 GRPO 같은 온라인 RL 방법론이 확산되면서 SFT는 출발선이 아니라 기본값이 되었다.
[SFT]
Driver (thin) → N개의 동일한 Worker → 각 Worker가 같은 학습 루프 실행
[Online RL]
Controller (active) → Policy Worker
→ Rollout Worker
→ Reward Model
→ Reference Model
→ 역할별 아티팩트(프롬프트, 궤적, 보상, 이점) 교환 및 수명주기 관리SFT에서 드라이버 노드는 "얇은(thin)" 역할이었다. N개의 동일한 Ray 액터를 실행하면 끝이었다. RL에서는 드라이버가 능동적인 컨트롤러로 진화해야 했다. 언제 롤아웃을 생성하고, 어떻게 배치를 처리하고, 언제 최적화를 트리거하고, 리소스를 어떻게 할당할지를 결정하는 제어 평면(control plane)이 된 것이다.
Netflix는 오픈소스 Verl 라이브러리의 Ray 액터 라이프사이클 관리를 통합해서, 분산 오케스트레이션을 처음부터 만들지 않고 RL 지원을 추가했다.
[💡 잠깐! 이 용어는?] SPMD(Single Program, Multiple Data): 모든 GPU 워커가 동일한 프로그램을 실행하되, 각각 다른 데이터 샤드를 처리하는 병렬 실행 모델이다. SFT처럼 단순한 학습 루프에 적합하다.
Hugging Face 생태계와의 공존 전략
흥미로운 설계 철학이 있다. Hugging Face를 단일 진실 공급원(single source of truth)으로 유지한다는 원칙이다.
초기에는 SentencePiece, tiktoken 같은 저수준 토크나이저에 직접 바인딩했다. 그런데 치명적 문제가 터졌다. 학습 시 토크나이저와 서빙 시(vLLM의 AutoTokenizer) 토크나이저 사이에 미묘한 차이가 생겨, 설명할 수 없는 품질 저하가 나타난 것이다. 정규화, 특수 토큰 처리, 채팅 템플릿의 아주 작은 차이가 토큰 경계를 다르게 만들었다.
반면 모델 구현은 다른 전략을 택했다. Hugging Face 모델 클래스를 직접 학습에 쓰지 않고, 내부 최적화 모델 정의를 유지하되 Hugging Face 체크포인트 호환성을 보장한다. 새 모델 패밀리를 지원할 때는 AI 코딩 에이전트로 변환 작업을 자동화하고, 로짓 검증기(logit verifier)로 랜덤 입력에 대해 Hugging Face 구현과 내부 구현의 로짓이 허용 범위 내에서 일치하는지 확인한다.
성능 최적화 — 어휘 크기 패딩의 교훈
프레임워크를 직접 소유하면 범용 도구에서는 신경 쓰지 않는 최적화를 할 수 있다. 대표적 사례가 어휘 크기 패딩이다.
Netflix의 워크로드는 시맨틱 ID나 특수 토큰을 빈번하게 추가한다. 특정 어휘 크기에서 언어 모델 헤드가 고도로 최적화된 cuBLAS 커널 대신 훨씬 느린 CUTLASS 경로로 폴백되면서, 해당 레이어 실행 시간이 3배로 뛰는 현상을 발견했다. 프레임워크에서 어휘 크기를 자동으로 64의 배수로 패딩해서 빠른 커널이 선택되도록 했다.
| 최적화 | 효과 |
|---|---|
| 온더플라이 시퀀스 패킹 | 유효 토큰 처리량 최대 4.7배 향상 |
| 어휘 크기 64 배수 패딩 | 모델 헤드 실행 시간 3배 단축 |
| 로짓 검증 기반 모델 지원 자동화 | 새 아키텍처 지원 시간 대폭 단축 |
마무리
Netflix의 Post-Training 프레임워크는 "LLM을 잘 학습시키는 비법"이 아니다. **"LLM 학습을 대규모로 반복 가능하게 만드는 엔지니어링"**에 관한 이야기다. Data, Model, Compute, Workflow 네 기둥으로 추상화를 나누고, 오픈소스 생태계를 적극 활용하되 Netflix 고유의 워크로드에 맞는 최적화를 얹는 전략이 인상적이다. SFT에서 RL로의 전환처럼, post-training의 프론티어는 빠르게 움직이고 있다. 이 변화에 대응하려면 "스크립트 모음"이 아니라 관리 가능한 시스템이 필요하다는 것이 Netflix가 전하는 메시지다.
같은 카테고리 · AI
비슷한 주제의 최신 글




태그가 겹치는 글
공통 태그가 많을수록 위에 보인다



